Initializer Jobs
Warning
This is not authoritative documentation. These features are not currently available in Zuul. They may change significantly before final implementation, or may never be fully completed.
The following specification describes a new type of job in Zuul to make it easier to create the “dispatch job” pattern.
Introduction
Zuul supports expressing dependencies between jobs and these may be used for a number of purposes, including:
Building an artifact once and testing it in multiple jobs
Establishing a shared resource for use of other jobs such as an image registry
Altering the
child_jobszuul_return value to skip running certain jobs (the “dispatch job” pattern)
The last two use cases sometimes involve setting every other job in the project-pipeline config to depend on a certain job. This can increase maintenance costs as jobs are added or removed from the configuration. It also makes the configuration difficult to read and understand.
Proposal
First, a note on terminology:
The correct terminology is dependencies and dependents, which is confusing, but it’s not appropriate to use terms like “parent” and “child” since we use those for inheritance. This is another dimension. To clarify the correct terminology using the wrong terms: the dependency is the parent and the dependent is the child. So if job A must run to completion before job B, then job A is a dependency of job B, and job B is a dependent of job A.
To simplify construction of dependencies, we can add a new type of job to Zuul that we will call an initializer job. Modeled after the “init container” in Kubernetes, or even the class initializer in object oriented programming, it will run at the start of a buildset before any other jobs.
Implementation
When the scheduler constructs the job graph for a buildset, it will
automatically make any initializer jobs that it encounters a
dependency of every other job listed in the project pipeline config.
After that point, behavior will be exactly as if the user had
explicitly specified these links. That means that the initializer job
may be used to filter dependents as well using zuul_return.
If more than one initializer job is specified, this process will be applied to all of them, in order, including the other initializer jobs. A job graph with 2 init jobs and one normal job would look like this:
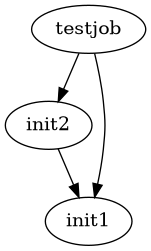
The result will be that the jobs run to completion individually in the following sequence:
init1
init2
testjob
There will be no explicit restriction on the use of dependencies by or against initializer jobs: users will be free to construct explicit dependencies in the usual manner. This may may result in errors if users construct an unsolvable graph. For example, an init job may not, in practice, depend on a non-init job since that non-init job would depend on the init job and create a cycle. The point here is that we aren’t creating any new rules, just relying on the existing ones.
If multiple initializer jobs run and return values using the
zuul.child_jobs variable via zuul_return, we will proceed with the
same behavior we have today if mulitple dependencies are run (which is
that the intersection of the results is what is run).
User Interface
A new job configuration attribute, type will be added, and an
initializer job will be created by specifying initializer as its
value. For example:
- job:
name: dispatch
type: initializer
The default type will be null, which represents a normal job (the
only type of job today).
Other Types of Jobs
There are currently no other special job types, but some have been contemplated and may be the subject of future proposals:
finalizer jobs
reporting jobs
The author of this spec is currently working on a spec for “reporting jobs”. It is not appropriate to review or discuss the designs of other potential jobs in this spec, however, they should be briefly noted to the degree they may impact decisions we may make here. We may never choose to implement any other types of jobs, but we should consider that we might, and if so, how we would design initializer jobs to accommodate them.
A finalizer job would simply be the complement of an initializer job. The very existence of an initializer job that runs at the start of a buildset causes us to imagine a similar job that runs at the end of a buildset. It could also be called a cleanup job.
A reporting job would be a type of job that runs during the reporting phase, after the end of the normal set of jobs.
With these potential future types of jobs, here are some questions for us to consider:
Are we okay with opening the door to special types of jobs like these? Once we add one, it will be harder to avoid adding more. Of course, each one can be evaluated independently.
How should we name the different types of jobs in order to make their usage and differences from each other clear. The proposed names of the jobs envisioned so far attempt to do so by using “initializer” and “finalizer” to indicate they run at the start and end of the buildset, and “reporting” to indicate it runs during the reporting phase.
Should we call the “initializer” job an “init” job? That is shorter, more convenient, and matches Kubernetes terminology (not to mention
__init__in Python). But we can’t call the “finalizer” a “final” job since we already have afinal: trueflag that means something else. We could call the “finalizer” a “destructor” but that suggests a purpose that may not match what the job actually does. Therefore, “finalizer” seems the best name for that, and “initializer” seems the best complimentary name.We don’t expect users to have to type it that often anyway.
How do the different job types relate to each other? The ones considered here are all mutually exclusive – they would run at three distinct phases and could not be used in more than one. Therefore, rather than adding three boolean flags to jobs, the proposal here is to add a single type attribute so it’s clear that a job may be only one type.
Alternatives
Considering only the initializer job: it is possible to achieve the desired behavior with explicit configuration today, but it is difficult to maintain. We could keep the status quo with no loss in functionality, at the cost of increased user confusion and maintenance burden.
Considering the other potential types of jobs: we might name this an init job instead, for convenience, but the rational for using initializer was described above.
Work Items
The work should be straightforward and is likely to be implemented in a single change.
Update configloader to support new syntax
Update model job graph freeze to add new behavior
Document
Add tests and a release note